-
[Elasticsearch] Elasticsearch 핵심 개념 설명IT 발자취.../Elastic Stack 2020. 4. 9. 01:02
일래스틱서치는 도큐먼트 지향 저장소로, JSON도큐먼트는 일래스틱서치에서 일급 객체로 취급한다.
이러한 JSON 도큐먼트는 다양한 타입과 인덱스로 구성된다.
- 인덱스 : 도큐먼트들의 모음
- 도큐먼트 : 필드들의 모음
- 필드 : 데이터를 key-value 형태로 저장한 것
기본적으로 Elasticsearch는 모든 필드에 있는 모든 데이터들을 색인한다.
각 색인된 필드들은 최적화된 전용 데이터 구조가 있다.
- 예를 들면, 텍스트 필드는 반전된 인덱스에 저장되고, 숫자 및 지리 필드는 BKD 트리에 저장
- 필드별 데이터 구조를 사용하여 검색 결과를 모으고 반환하는 기능은 Elasticsearch를 매우 빠르게 만듬
Elasticsearch에는 스키마가 없어도 됩니다. 즉, 도큐먼트에서 발생할 수 있는 각기 다른 필드를 처리하는 방법을 명시적으로 지정하지 않고도 도큐먼트를 색인화 할 수 있다.
Dynamic 매핑이 가능하면, Elasticsearch는 자동으로 새로운 필드를 찾고 인덱스에 추가한다. 이러한 기본 행위는 인덱스와 데이터 탐색을 쉽게 한다.
도큐먼트를 인덱싱하기 시작하고 Elasticsearch는 booleans, floating point와 정수값, 날짜 그리고 문자열을 적절한 Elasticsearch의 데이터 타입으로 매핑한다.
다이나믹 매핑을 조정하기 위해 규칙을 설정하여 어떻게 필드가 저장되거나 인덱스될지 전체적으로 조정가능하다.
키워드
인덱스 ( Index )
Elasticsearch에서 단일 타입의 도큐먼트를 저장하고 관리하는 컨테이너다.
인덱스는 아래 그림과 같이 여러 개의 단일 타입 도큐먼트를 가질 수 있다. ( 6.0 이전 버전 )
- 6.0 이후 버전은 하나의 인덱스에 단 하나의 타입만 가질 수 있도록 변경
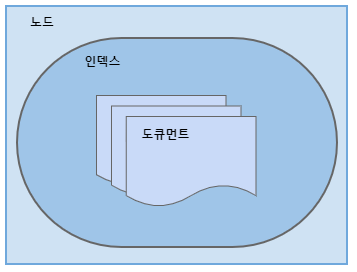
도큐먼트 ( Document )
JSON 도큐먼트는 엘라스틱서치에서 일급 객체로 취급된다. 다중 필드로 구성된 도큐먼트는 엘라스틱서치에서 저장된 정보의 기본 단위다.
예 > 단일 제품, 단일 고객, 단일 주문 항목을 표헌하는 도큐먼트가 있을 수 있다.
각 필드와 필드 값은 도큐먼트에서 키와 값 쌍으로 확인 할 수 있다. ( 키는 필드 이름, 값을 필드 값이다. )
필드 이름은 RDB에서 열 이름과 유사하다. 필드 값은 주어진 행에 대한 열이 가진 값, 즉 테이블에서 주어진 셀 값으로 볼 수 있다.
엘라스틱서치에서 도큐먼트는 사용자가 정의한 필드 외에도 다음과 같이 내부적으로 메타 필드를 갖고 있다.
- _id : 데이터 베이스 테이블의 기본키처럼 인덱스 내 도큐먼트의 고유 식별자다. 자동 생성되거나 사용자가 정의할 수 있다.
- _type : 도큐먼트의 타입을 포함한다.
- _index : 도큐먼트의 인덱스 이름을 포함한다.
클러스터 ( Cluster )
클러스터는 단일 혹은 다중 인덱스를 호스팅하며 검색, 색인, 집계와 같은 연산을 제공한다.
클러스터는 하나 이상의 노드로 구성된다. 모든 엘라스틱서치 노드는 항상 클러스터의 부분 집합이다.
단일 노드 클러스터라 하더라도 해당 노드는 클러스터의 일부라고 볼 수 있다.
기본적으로 모든 엘라스틱서치 노드는 elasticsearch라는 이름의 클러스터에 참여하려고 한다.
config/elaticsearch.yml 파일에서 cluster.name 속성을 변경하지 않고 같은 네트워크에서 여러 노드를 시작하면 클러스터가 자동으로 구성된다.
노드 ( Node )
엘라스틱 서치는 분산 시스템이다. 네트워크에 위치한 각 시스템에서 실행되고, 다른 프로세스와 통신하는 다중 프로세스로 구성된다.
엘라스틱서치 노드는 대형 클러스터 노드의 부분 집합이 될 수 있는 단일 서버를 말한다.
노드는 엘라스틱 서치에서 지원하는 색인, 검색 및 기타 연산 작업을 수행한다.
샤드 ( Shard ) 및 복제본 ( Replica )
샤드
샤드는 클러스터에서 인덱스를 분배하고 단일 인덱스의 도큐먼트를 여러 노드로 분할하는데 유용하다.
단일 노드에 저장할 수 있는 데이터양에는 제한이 있으며, 그 한계는 노드의 저장소, 메모리, 처리 용량에 따라 결정된다.
따라서 샤드를 활용하면 클러스터에서 단일 인덱스 데이터를 분할해 클러스터의 저장소와 메모리, 처리 용량에 적절히 활용할 수 있다.
샤드에 위치한 데이터를 분할하는 과정을 샤딩(sharding)이라고 한다. 샤딩은 엘라스틱서치에 내장된 고유 기능이며, 다음과 같이 확장 및 병렬화 기능을 담당한다.
- 클러스터에 위치한 여러 노드의 저장소 활용을 돕는다.
- 클러스터에 위치한 여러 노드의 처리 능력 활용을 돕는다.
기본적으로 모든 인덱스는 엘라스틱서치에서 5개의 샤드를 갖도록 구성된다. 인덱스 생성 시점에 인덱스의 데이터를 나눌 샤드 갯수를 지정할 수 있다. 인덱스를 생성하고 나면 샤드 갯수는 변경할 수 없다.
다음 그림은 3개의 노드로 구성된 클러스터에서 5개의 샤드를 가진 인덱스가 어떻게 분산되는지 보여준다.
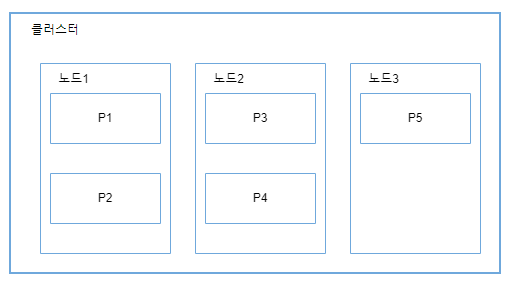
그림에서 샤드 이름은 P1에서 P5로 지정됐으며, 각 샤드는 인덱스에 저장된 전체 데이터에서 약 1/5을 포함한다.
인덱스에 쿼리를 수행하면 엘라스틱서치는 모든 요청을 보낸 후, 결과를 통합한다. 이제 클러스터에서 노드1에 장애가 발생한다고 가정해본다.
이런 경우, 노드1에 위치한 샤드 P1과 P2에 저장된 데이터 조각이 손실된다.
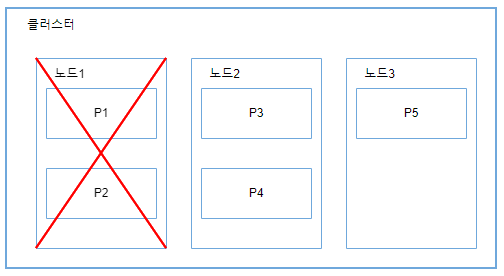
엘라스틱서치와 같은 분산 시스템에서는 하드웨어 장애 상황에서도 문제없이 실행돼야 한다.
엘라스틱서치에서는 replica shard 또는 replica라고 부르는 복제본 Replica로 문제를 해결한다.
복제본
인덱스의 각 샤드는 0개 이상의 복제본을 가질 수 있다.
따라서 복제본은 데이터의 높은 가용성을 제공하기 위한 원본 샤드의 추가 사본을 의미한다.
예를 들어, 각 샤드가 하나의 복제본을 가진다고 가정하면, 다음 그림의 각 샤드별로 복제본을 하나씩 가진 주 샤드 (primary shard) 5개를 나타낸다.

주 샤드는 녹색, 복제본은 노란색으로 표시된다. 노드1에 장애가 발생하더라도 노드2와 노드3이 사용할 수 있는 모든 샤드를 가지고 있다. 복제본은 해당 주 샤드에 장애가 발생하면 주 샤드로 승격될 수 있다.
복제본은 고가용성 및 장애조치 기능 외에도 쿼리 작업을 수행할 수 있다.
즉, 검색, 쿼리, 집계와 같은 읽기 연산은 복제본에서 실행될 수 있다. 엘라스틱서치는 쿼리 실행을 샤드 또는 복제본이 위치한 클러스터 노드 전반에 걸쳐 정직하게 분배한다.
매핑 ( Mapping ) 및 타입
엘라스틱서치는 스키마가 존재하지 않는다. 즉, 필드와 필드 타입 없이도 얼마든지 도큐먼트를 저장할 수 있다.
하지만 실제 운영 환경에서 사용하는 데이터는 스키마가 존재하고 체계화된 구조를 갖는다.
특정 타입의 모든 도큐먼트는 항상 공통 필드 집합이 있다.
실제로 인덱스 타입은 공통 필드를 기반으로 생성해야 한다. 일반적으로 인덱스에서 하나의 타입을 가진 도큐먼트는 몇 가지 공통 필드를 공유한다.
반명 RDB는 엄격한 구조를 요구한다. RDB에서는 테이블 생성 시점에 각 열 이름과 타입을 지정하는 등 테이블 구조를 정의해야 한다.
실행 중에는 새로운 이름을 갖거나 다른 데이터 타입을 가진 열을 레코드로 저장할 수 없다.
따라서 엘라스틱서치에서 지원하는 데이터 타입을 이해하는 것이 중요하다.
역색인 ( Inverted Index )
역색인은 엘라스틱서치와 전문 텍스트 검색을 지원하는 시스템에서 핵심 데이터 구조다.
역색인은 책의 끝에 나오는 색인 목록과 유사하다. 도큐먼트에 나타난 용어를 도큐먼트에 매핑하는 방식으로 사용한다. 예를 들면, 다음 문자열에서 역색인을 만들 수 있다.

엘라스틱서치는 색인된 3개의 도큐먼트에 대해 다음과 같이 데이터 구조를 생성하며, 이를 역색인이라고 부른다.

다음 사항에 유의해야 한다.
- 용어는 도큐먼트에서 구두점을 제거하고 소문자로 치환한 후 분리된 글자를 나타낸다.
- 용어는 알파벳순으로 정렬된다.
- 빈도 열은 전체 도큐먼트에 용어가 얼마나 많이 나타났는지 알려준다.
- 세 번째 열은 용어가 속한 도큐먼트를 나타낸다.
- 용어가 위치한 정확한 도큐먼트의 오프셋을 포함할 수 있다.
도큐먼트에서 용어를 검색할 때, 검색하는 용어가 도큐먼트에서 표시되는 속도는 엄청나게 빠르다.
검색이 빠른 이유는 인덱스에서 용어가 정렬돼 있기 때문이다. 사용자가 특정 용어를 검색하면 정렬된 용어에서 해당하는 열만 찾으면 된다.
마찬가지로 수백만 개의 단어를 검색하는 상황을 생각해보자. 역색인을 이용하면 last sunday처럼 두 단어를 검색하는 상황을 생각해 보자.
역색인을 이용하면 last와 sunday가 포함된 도큐먼트를 개별적으로 검색할 수 있다. 도큐먼트에 2개의 용어가 모두 포함된다면 하나의 용어만 포함하는 도큐먼트보다 더 적합하다고 판단할 수 있다.
역색인은 검색을 빠르게 수행하기 위한 기본 요소다. 마찬가지로 인덱스에 용어가 몇 번이나 나타났는지도 손쉽게 조회할 수 있다.
이는 간단한 개수 집계 기능이다. 마찬가지로 엘라스틱서치는 여기에서 설명한 가장 기본적인 역색인 외에도 여러 혁신적인 기능을 적용해 검색과 분석에 대한 요구 사항을 지원한다.
기본적으로 엘라스틱서치는 도큐먼트의 모든 필드에 역색인을 작성하고, 필드가 나타난 엘라스틱서치 도큐먼트를 가리키도록 만단다.
'IT 발자취... > Elastic Stack' 카테고리의 다른 글
[Elasticsearch] 핵심 개념 - 매핑 타입이 사라지면서 멀티 타입 인덱스를 싱글 타입 인덱스로 마이그래이션 (0) 2020.04.09 [Elasticsearch] 핵심 개념 - 매핑 타입이 사라진 이유 (0) 2020.04.09 [Elasticsearch] 집계 기초 (0) 2018.12.24 [Elasticsearch] 검색 API 기초 (0) 2018.12.23 [kibana] 0. kibana install ( 키바나 설치 ) (0) 2018.12.23 댓글